
LLMs in Production
If you thought using LLMs in Production was just another API call, think again.

We’ve had quite a bit of experience building products where a big focus has been on using LLMs as a core part of the product, and throughout that time, we’ve noticed a big difference between “playing around with LLMs in Development” and actually deploying them into the wild, to be used by customers.
Spoiler: LLMs in Production is a very different ballgame from just testing things in a contained environment when the only user is you.
If you’re thinking of seriously using Large Language Models in your product here’s a couple of things we wish we’d focused on beforehand and would recommend doing so you don’t make the same mistakes as us!
Note: our learnings are from building Dolphin AI and Pretty Prompt. Using LLMs with millions of tokens and thousands of daily requests with real Production data.
Observability 👀
The first thing you need to think of is observability. This is key. If you don’t know how people are using your LLMs, a lot of decisions made downstream are just guesswork.
It's like flying a plane without instruments in stormy weather. 🌩️
LLMs are the new electricity, so every drop (or token) is going to incur a cost. Both financially but also in terms of latency.
There's a load of great tools to use out there (e.g. Helicone or KeywordsAI are great for getting started, and as you grow, there are some more enterprise-y tools available too). The important thing to consider is reliability for these, and that you trust what you’re seeing in the logs is actually what’s coming through.
Three elements to keep in mind with observability: Cost - Latency - Bugs.
Cost
You’ll want to know how much each LLM request is costing you, literally in terms of dollars. I’ve yet to find a good forecasting tool for this but you can roughly extrapolate from a single “super user” with some back-of-the-napkin math to calculate whether using GPT-5 or Claude-Opus-4.1 is going to send your company’s economics into the red.
You want to know how much each request is costing you, how much each step is costing you (if you have complex workflows or AI Agents in the background), and how much each user is costing you.
Latency
You want to know how long each request is taking because while GPT-5 might have PhD-level intelligence, if it's taking more than 30 seconds to resolve, that's going to leave your users twiddling their thumbs and impact your overall product's UX…
…And ultimately your product’s magic.
It’s like flipping a switch and having to wait a minute for the light to come on. You’d call your electrician pronto.
Quite often, we’ve found it's better to use a slightly faster/smaller model and restrict the prompt parameters e.g. if you have a very specific task it can be better to use a “nano” or “mini” version of the model and iterate on the prompting than it is to use the larger model provided you can achieve same quality of output.
Bugs
Finally, observability will help you debug a lot faster. If a request is failing because of some API key that's been incorrectly typed, you'll know within a couple of seconds of looking through your logs (we had almost this exact same case a few weeks ago 🤦 … And were able to identify, resolve it, and ship an update to Production in under 10 minutes because we had observability set up).
Stochastic vs. Deterministic Outputs 😵💫
Dealing with LLMs quite often means you don't actually know what you're going to get out of the “magic black box” of back-propagation.
This presents a problem because of programming types. What is the data type the LLM is going to output? A JSON? Text? Number? Float? Markdown?
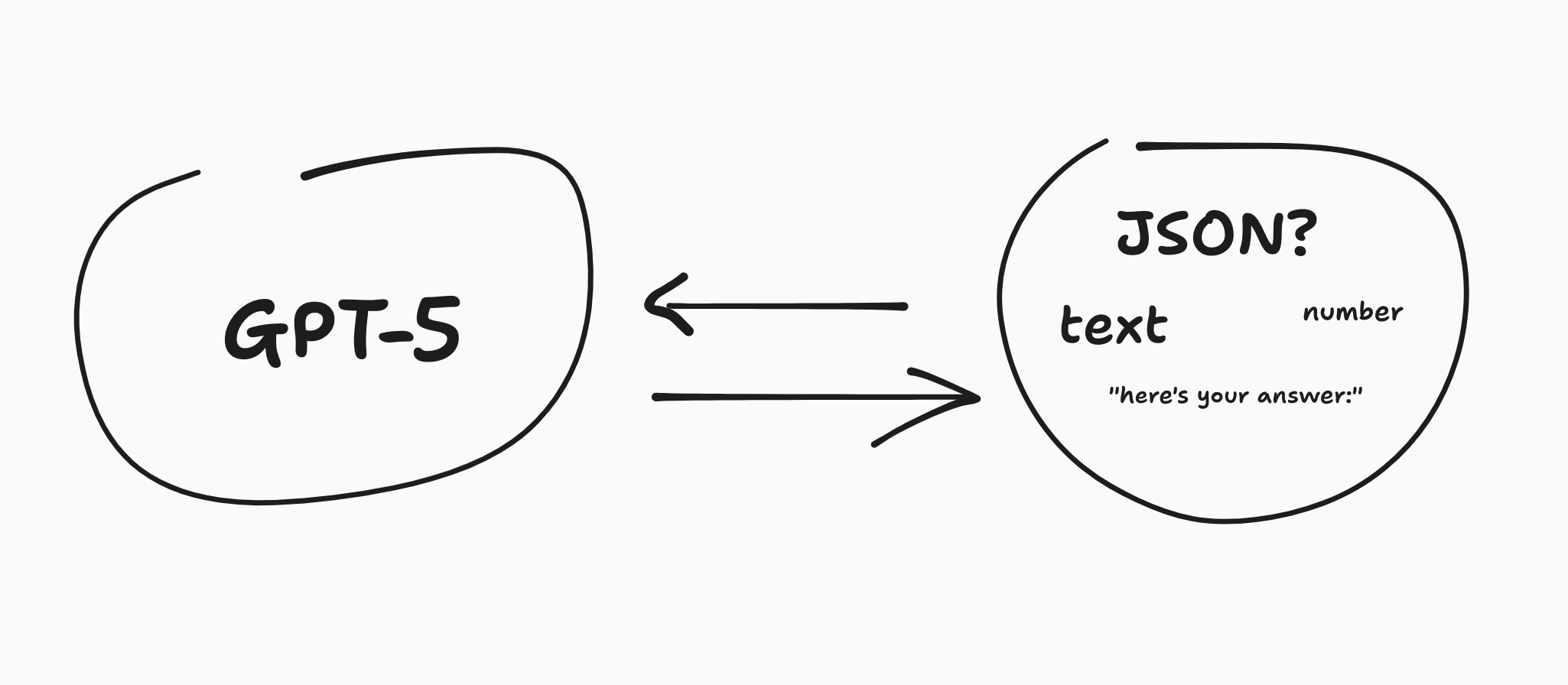
This is important because if you're passing that through other functions in your codebase, they will expect to be given a certain argument type (e.g. string, object, boolean, number etc.) and even things like TypeScript can't save you here…
You need to enforce it on the request going into the LLM. You could ask the model to output in a specific JSON, but I've found quite often it can be a bit meh, and if it misses a single bracket or comma, it's useless. It’ll also sometimes prefix a “here’s your JSON response:” followed by perfect JSON, which completely defeats the point!
Function Calling / Structured Output
That's where Function Calling comes in. On most models, you'll have a way to insert a specific schema in a JSON format and dictate the types.
This means you'll get the exact JSON outputted from the model and not just a string of text. You can then just forward that into the rest of your codebase, confident you’re not going to get some type error later down the line.
Quick note, there's probably some issues around prompt injection here that haven’t really been deeply understood yet, so you'd still want to validate what's going into your functions. This is especially if they're calling your database, i.e. you want to make sure the LLM isn’t going to run a DROP on your User table.
Error Handling 🫠
While using LLMs at scale, you will find they fail. A lot. You don’t catch this at all in Development because you’re likely only running a couple of dozen requests. When you start ramping up to running thousands of requests/day (something we had to learn the hard way at Pretty Prompt), you will almost definitely hit these problems.
Worst of all, it's quite often not because of you. It’s the providers. I see 500 errors in my sleep…
For example, even writing this today (September 1st), Google's general API for all their LLMs are experiencing "partial outage" which translates in Production to about 50% of your requests just straight up failing with often no information as to why.
"Sorry, an internal error occurred".
This is where provider dependency really matters, and unless you have some enterprise SLA deal with the big players that guarantees some form of uptime, you'll likely have to improvise.
The good news is that the nearer LLMs converge towards becoming a commodity, the easier it is to switch on the fly. You can use something like LangChain or even do it yourself (my preference, so you can understand the quirks of each model).
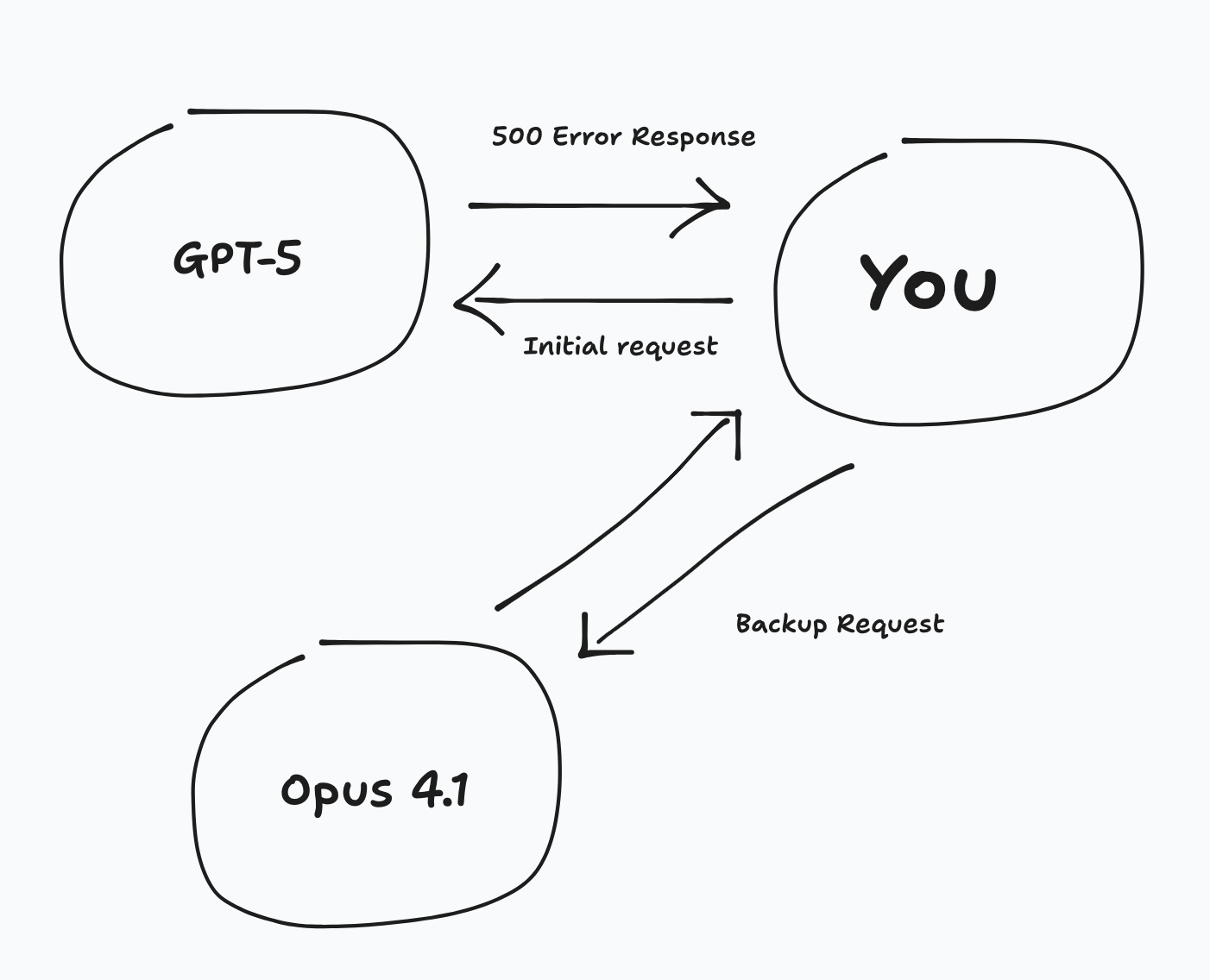
Obviously this incurs a bit of extra latency, but it limits the errors your users will experience, and from their point of view, it's just a couple of seconds slower.
There’s still a whole bunch of things we haven’t covered with using LLMs in Production, such as:
Caching duplicate requests
Checking for large contexts
Rate limiting
Including and managing context
Making your LLMs more agentic
But that’s for another day.
TL;DR
Use an observability platform from day 1.
Use structured outputs or function calling for predictive outputs.
Always have a backup provider in the (very likely) event of downtime (even the mighty Google has extended downtime).